살펴볼 내용
- 생성하기
- 배열 / 컬렌션 / 빈 스트림
- Stream.builder() / Stream.generate() / Stream.iterate()
- 기본 타입형 / String / 파일 스트림
- 병렬 스트림 / 스트림 연결하기
- 가공하기
- Filtering
- Mapping
- Sorting
- Iterating
- 결과 만들기
- Calculating
- Reduction
- Collecting
- Matching
- Iterating
스트림 ( Streams )
자바8 에서 추가된 스트림(Streams) 은 람다를 활용할 수 있는 기술 중 하나입니다. 자바8 이전에는 배열 또는 컬렉션 인스턴스를 다루는 방법은 for 또는 for-each 문을 돌면서 요소 하나씩을 꺼내서 다루는 방법이었습니다. 로직이 복잡해 질수록
코드의 양이 많아져 여러 로직이 섞이게 되고, 메소드를 나눌 경우 루프를 여러 번 도는 경우가 발생합니다.
스트림은 '데이터의 흐름' 입니다. 배열 또는 컬렉션 인스턴스에 함수 여러 개를 조합해서 원하는 결과를 필터링하고 가공된 결과를 얻을 수 있습니다. 또한 람다를 이용해서 코드의 양을 줄이고 간결하게 표현할 수 있습니다. 즉, 배열과 컬렉션을 함수형으로 처리할 수 있습니다.
스트림은 파일 I/O에서 사용되는 스트림과는 다르다. 데이터 소스를 추상화하고, 데이터를 다루는데 자주 사용되는 메소드들을 정의해 놓았다. 데이터 소스를 추상화 하였다는 것은, 데이터 소스가 무엇이든 같은 방식으로 다룰 수 있게 되었다는 것과 코드의 재사용성이 높아진다는 것을 의미한다.
스트림의 특징
- 스트림은 데이터 소스를 변경하지 않는다.
- 스트림은 데이터 소스로 부터 데이터를 읽기만할 뿐, 데이터 소스를 변경하지 않는다. 필요하다면, 정렬된 결과를 컬렉션이나 배열에 담아서 반활할 수 있다.
- 스트림은 일회용이다
- 스트림은 Iterator 처럼 일회용이다. Iterator 로 컬렉션의 요소를 모두 읽고 나면 다시 사용할 수 없는 것처럼, 스트림도 한번 사용하면 닫혀서 다시는 사용할 수 없다. 필요하다면 스트림을 다시 생성해야한다.
- 스트림은 작업을 내부 반복으로 처리한다.
- 스트림을 이용한 작업이 간결할 수 있는 비결중의 하나가 바로 '내부 반복'이다. 내부 반복이라는 것은 반복문을 메서드의 내부에 숨길 수 있다는 것을 의미한다.
- 스트림은 원본 데이터를 변경하지 않는다.
- 스트림의 연산은 필터-맵 ( filter - map ) 기반의 API 를 사용하여 지연 ( lazy ) 연산을 통해 성능을 최적화한다.
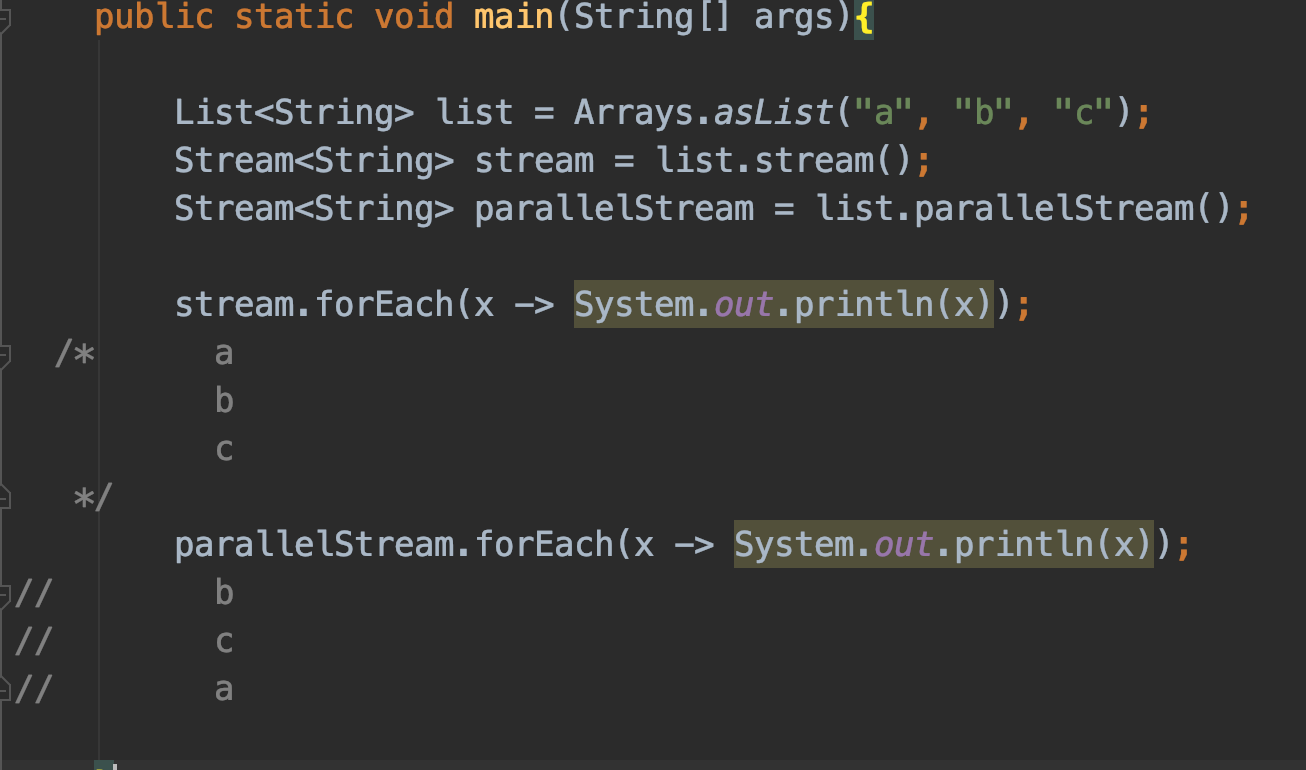
- 스트림은 parallelStream() 메소드를 통한 손쉬운 병렬 처리를 지원한다.
스트림 API 의 동작 흐름
1. 스트림 생성 : 스트림 인스턴스 생성.
2. 스트림 중개 연산 ( 스트림 변환, 가공) : 필터링 ( Filtering ) 및 매핑 ( Mapping ) 등 원하는 결과를 만들어가는 중간 작업.
3. 스트림 최종 연산 ( 스트림 사용, 결과 ) : 최종적으로 결과를 만들어내는 작업
생성하기
배열 스트림
스트림을 이용하기 위해서는 먼저 생성을 해야 합니다. 스트림은 배열 또는 컬렉션 인스턴스를 이용해서 생성할 수 있습니다. 배열은 다음과 같이 Arrays.stream 메소드를 사용합니다.

컬렉션 스트림
컬렉션 타입 ( Collection, List, Set ) 의 경우 인터페이스에 추가된 디폴트 메소드 stream 을 이용해서 스트림을 만들 수 있습니다.

다음과 같이 생성할 수 있다
스트림 사용법과 주의사항
스트림의 구조는 크게 3가지로 나뉜다.
1. 스트림생성
2. 중개 연산
3. 최종 연산
-> 실제 사용법으로 표기하면 "Collection 같은 객체 집합.스트림생성().중개연산().최종연산();" 이런식이다.
Stream은 주로 Collection, Arrays 에서 쓰인다.
물론 두 개 뿐만 아니라 I/O resources( ex. File ) , Generators, Stream ranges, Pattern 등에서도 사용할 수 있다.
- 중개 연산 ( Intermediate Operation )
Filtering - filter(), distinct()
Mapping - map(), flatMap()
Restricting - limit(), skip()
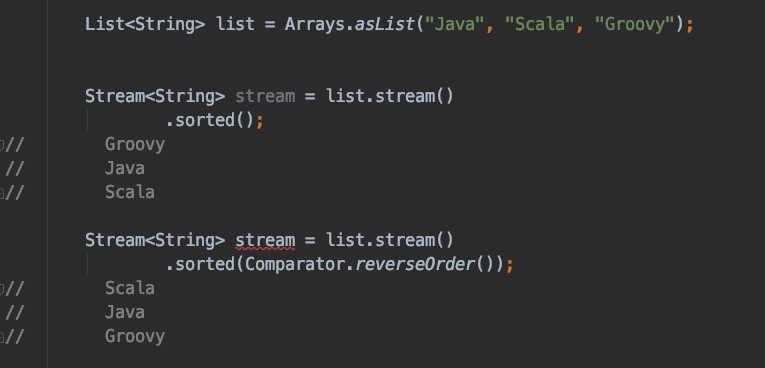
Sorting - sorted()
Iterating - peek()
# Filtering
Filtering 은 스트림 내 요소들을 하나씩 평가해서 걸러내는 작업이다. 인자로 받는 Predicate 는 boolean 을 리턴하는 함수형 인터페이스로 평가식에 들어가게 된다.
distinct()
해당 메소드는 스트림에서 중복된 요소가 제거된 새로운 스트림을 반환하며, 내부적으로 Object 클래스의 equals() 메소드를 사용하여 요소의 중복을 비교한다.
filter()
해당 메소드는 해당 스트림에서 주어진 조건(predicate)에 맞는 요소만으로 구성된 새로운 스트림을 반환한다.
예제<>

스트림의 각 요소에 대해서 평가식을 실행하게 되고, 평가식에 충족한 값들만 들어간 스트림이 리턴된다.
# Mapping
Mapping 은 스트림에 들어가 있는 값이 input이 되어 특정 로직을 거친 후 output 이 되어 새로운 스트림에 담는 작업이다.
map()
메소드는 스트림 내 요소들을 하나씩 특정 값으로 변환해준다. 이 때 값을 변환하기 위한 람다식을 인자로 받는다.

flatMap()
메소드는 변환하려는 해당 스트림의 요소가 배열일 때 사용한다.
인자로 mapper를 받고, 리턴 타입은 Stream 이다. 즉, 새로운 스트림을 생성해서 리턴하는 람다를 넘겨줘야한다. flatMap은 중첩 구조를 한 단계 제거하고 단일 컬렉션으로 만들어주는 역할을 하며, 이러한 작업을 플래트닝(flattening)이라고 한다.

위에서 중첩 구조 (이중 리스트)를 제거하고 작업할 수 있다.
밑의 코드처럼 객체에서 적용이 가능하다. student 객첼르 담고있는 리스트를 스트림으로 생성하고, 객체가 가지고 있는 각 과목 점수를 flatMap을 이용하여 접근이 가능하다.
# Restricting
limit()
메소드는 해당 스트림의 첫 번째 요소부터 전달된 개수만큼의 요소만으로 새로운 스트림을 구성한다. 앞 포스팅의 스트림 생성에서 Stream.generate(), Stream.iterate() 의 예제에서도 잠깐 쓰였던 메솓이다. skip() 메소드와 혼용이 가능하다.
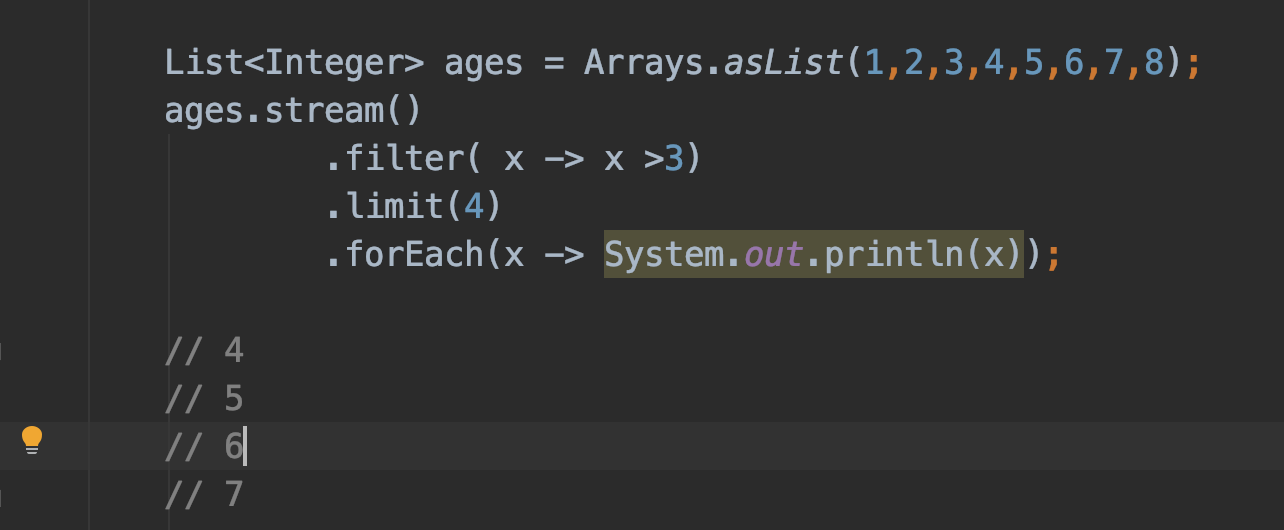
Skip()
해당 스트림의 첫 번째 요소부터 전달된 개수만큼의 요소를 제외한 나머지 요소만으로 새로운 스트림을 구성한다. limit() 메소드와 혼용이 가능하다.

Filter

filer 는 말 그대로 필터링, 즉 조건에 맞는 것만 거른다는 것이다.
위의 코드에서는 람다식을 이용해서 x 로 스트림의 요소를 받고 각 요소에 "O" 라는 알파벳이 있는 것들만 거른다.
Map
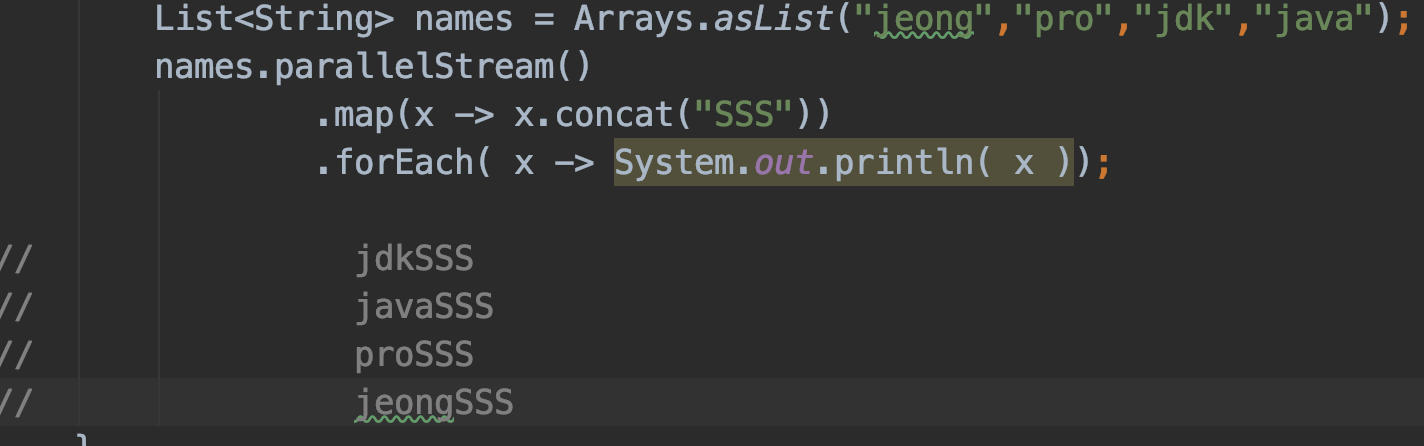
map 은 스크림의 각 요소를 연산하는데 쓰인다. 위와 같은 경우에는 각 문자열(요소) 마다 뒤에 "s"를 붙였다. 숫자일 경우 *2 로 두 배를 만든다든지 등의 다양한 조작이 가능하다.
Sorted
메소드는 해당 스트림을 주어진 비교자(Comparator)를 이용하여 정렬한다. 이 때, 비교자를 전달하지 않으면 기본적으로 사전 순으로(natural order)정렬된다.


Limit
스트림의 개수를 .limit(3) 으로 지정하면 3개로 제한한다. ( 물론 중개연산이라 스트림 반환 )
# Iterating
peek()
각각을 대상으로 특정 연산을 수행하는 메소드로 peek() 이 있다. 이 메소드는 원본 스트림에서 요소를 소모하지 않으므로, 주로 연산과 연산 사이에 결과를 확인하기 위해 사용된다. (디버깅 용도로 많이 사용된다.)
아무 것도 반환하지 않는 함수형 인터페이스 Consumer 를 인자로 받는다.